Google Gemini 3.1 Flash-Lite: Respuestas 2,5 veces más rápidas y razonamiento adaptativo para acelerar el procesamiento masivo de datos
Google lanza Gemini 3.1 Flash-Lite, un modelo con respuestas 2,5 veces más rápidas y razonamiento adaptativo. Permite procesar datos masivos en tiempo real con un coste muy reducido.

Crear software con inteligencia artificial requiere procesar grandes cantidades de datos de forma rápida para que los proyectos sean viables. Por esta razón, Google presentó Gemini 3.1 Flash-Lite el 3 de marzo de 2026. Esta versión cuenta con una arquitectura optimizada que hace que la primera respuesta sea 2,5 veces más rápida que antes. Su mayor avance es el razonamiento adaptativo, que utiliza menos recursos computacionales.
Arquitectura algorítmica y niveles de razonamiento adaptativo
Gemini 3.1 Flash-Lite está construido sobre la base de Gemini 3 Pro y utiliza la infraestructura TPU de Google para mejorar la eficiencia energética. Los desarrolladores pueden ajustar la profundidad del cálculo del modelo según la tarea. Por ejemplo, tareas simples como traducir textos se realizan al instante sin consumir recursos innecesarios. En tareas más complejas, como crear interfaces de usuario, el sistema dedica más tiempo al razonamiento solo cuando hace falta.
Capacidad de memoria temporal y procesamiento de contexto
El modelo es capaz de procesar hasta un millón de tokens de entrada y generar hasta 65.536 tokens de salida por instrucción. Esto facilita trabajar con documentos extensos, videos largos o grandes repositorios de código en una sola consulta.
Integración multimodal y ejecución de tareas de alto volumen
Gemini 3.1 Flash-Lite puede procesar texto, imágenes, audio y video simultáneamente como datos de entrada. Con una latencia más baja, el rendimiento mejora un 45% comparado con versiones anteriores. Esta velocidad permite implementar sistemas de moderación de contenido en tiempo real a gran escala. Las respuestas llegan rápido y mejoran la atención al cliente sin los retrasos comunes.
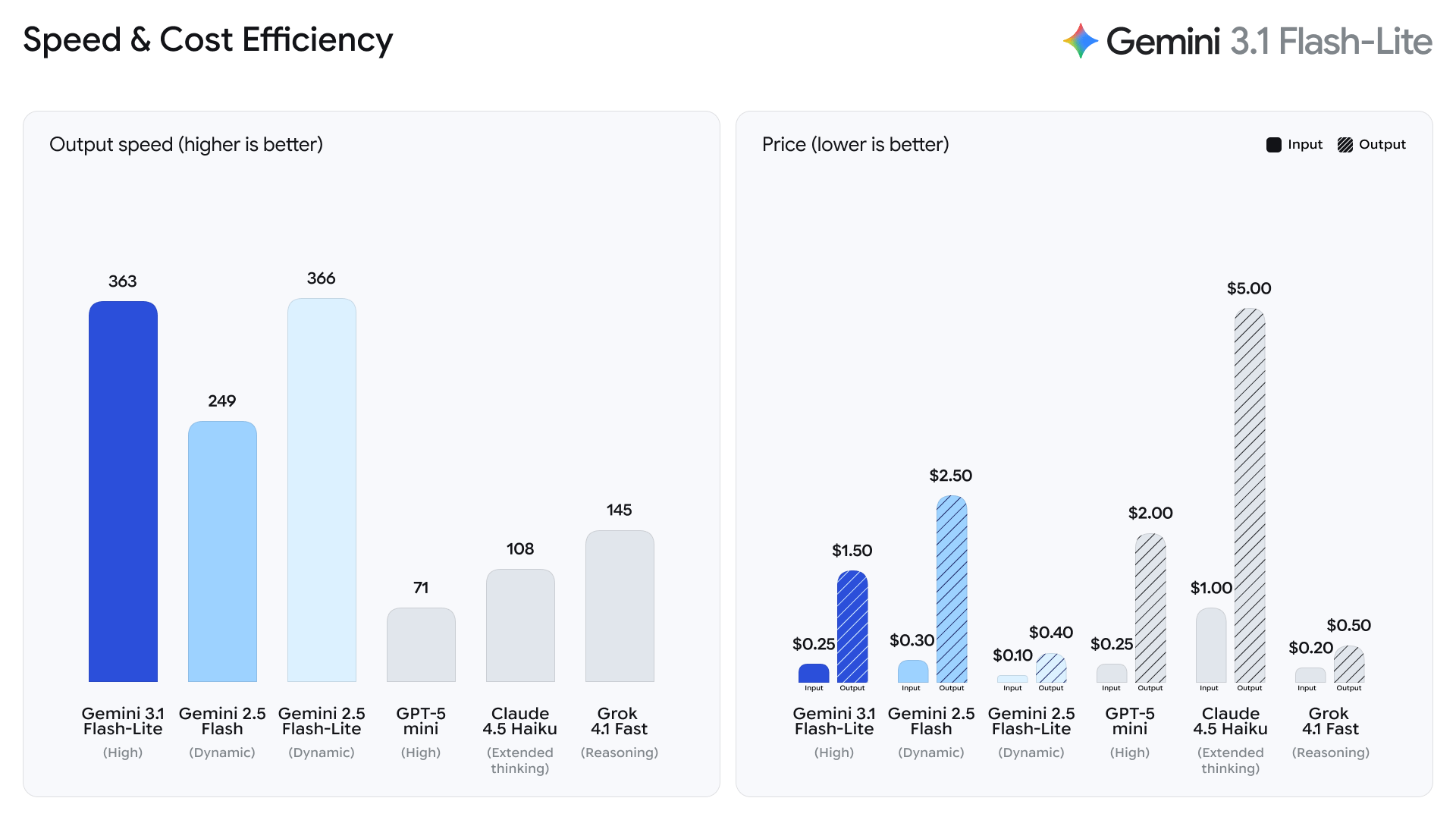
Gemini 3.1 Flash-Lite empezó su despliegue global en fase preliminar el 3 de marzo de 2026 y está disponible en Google AI Studio y Vertex AI. El precio base es de 0,25 dólares por millón de tokens de entrada y 1,50 dólares por millón de tokens de salida, lo que lo hace ocho veces más económico que Gemini 3.1 Pro. Este modelo está dirigido a startups y desarrolladores que gestionan grandes volúmenes de llamadas al servidor.


